 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Research as Rubric for Reinforcement Learning
May 31, 2026Open-ended reasoning and long-form generation tasks lack reliable automatic verification signals for reward-based policy optimization. Rubrics offer a promising alternative, but existing approaches treat them as given artifacts -- either hand-crafted or prompt-generated -- and often miss the task-specific, knowledge-intensive dimensions that matter most, distorting the reward signal. Our key observation is that rubric construction is itself a research problem: identifying what makes a response correct or insightful requires discovering and synthesizing external knowledge. We propose Deep Research as Rubric (DR-rubric), a two-stage framework for constructing such rubrics. Stage I elicits domain facts, structural constraints, and failure modes through iterative multi-turn agentic search; Stage II distills this evidence into atomic, independently verifiable constraints for GRPO-based policy optimization. Because the model under training can serve as its own rubric generator, DR-rubric-8B supports bootstrap rubric generation without frontier-model assistance. We evaluate on 6 benchmarks spanning agentic research and expert reasoning. Experiments show that DR-Rubric achieves strong competitive performance with only 1K -- 3K training instances, where GPT-5-generated rubrics particularly benefit breadth coverage on agentic tasks, Gemini-generated rubrics yield the most balanced performance across agentic and expert reasoning tasks, and bootstrap rubrics exhibit a specialization-to-rebalancing evolution achieving the best overall performance at the third iteration. Results demonstrate that reframing rubric construction from static evaluation templates into an evidence-driven research process yields more scalable, fine-grained reward signals for open-ended tasks.
Scaling Behavior of Single LLM-Driven Multi-Agent Systems
May 30, 2026The burgeoning field of LLM-based Multi-Agent Systems (MAS) promises to tackle complex tasks through collaborative intelligence, yet fundamental questions regarding their scaling behavior and intrinsic collective dynamics remain underexplored. This paper systematically investigates how the performance of a homogeneous MAS evolves as the number of agents increases, isolating the variable of collaboration from model or knowledge heterogeneity. We propose the Sequential Iterative Multi-Agent System (SIMAS) framework, a minimalist architecture centered on sequential inter-agent communication, to clearly observe scaling effects. Through extensive experiments across diverse tasks and model scales, we establish that MAS performance does not scale monotonically with agent count but follows a pattern of diminishing returns, governed by a trade-off between collaborative synergy and coordination overhead. Our findings reveal that effective MAS requires a sufficiently capable base LLM, that task type critically modulates the optimal agent count, and that collective intelligence is an emergent property contingent on strategic interaction design rather than a guaranteed outcome of agent plurality. The performance degradation stems coordination overhead rather than merely long-context failure, and the scaling tendency generalizes across interaction architectures like structured debate topologies. This work provides a foundational understanding of MAS scaling laws, offering practical guidance for designing efficient collaborative systems and challenging the prevailing assumption that more agents invariably lead to better performance.
ScholarGym: Benchmarking Deep Research Workflows on Academic Literature Retrieval
Jan 29, 2026Tool-augmented large language models have advanced from single-turn question answering to deep research workflows that iteratively plan queries, invoke external tools, and synthesize information to address complex information needs. Evaluating such workflows presents a fundamental challenge: reliance on live APIs introduces non-determinism, as tool invocations may yield different results across runs due to temporal drift, rate limiting, and evolving backend states. This variance undermines reproducibility and invalidates cross-system comparisons. We present ScholarGym, a simulation environment for reproducible evaluation of deep research workflows on academic literature. The environment decouples workflow components into query planning, tool invocation, and relevance assessment, enabling fine-grained analysis of each stage under controlled conditions. Built on a static corpus of 570K papers with deterministic retrieval, ScholarGym provides 2,536 queries with expert-annotated ground truth. Experiments across diverse backbone models reveal how reasoning capabilities, planning strategies, and selection mechanisms interact over iterative refinement.
MARO: Learning Stronger Reasoning from Social Interaction
Jan 18, 2026Humans face countless scenarios that require reasoning and judgment in daily life. However, existing large language model training methods primarily allow models to learn from existing textual content or solve predetermined problems, lacking experience in real scenarios involving interaction, negotiation, and competition with others. To address this, this paper proposes Multi-Agent Reward Optimization (MARO), a method that enables large language models (LLMs) to acquire stronger reasoning abilities by learning and practicing in multi-agent social environments. Specifically, MARO first addresses the sparse learning signal problem by decomposing final success or failure outcomes into each specific behavior during the interaction process; second, it handles the uneven role distribution problem by balancing the training sample weights of different roles; finally, it addresses environmental instability issues by directly evaluating the utility of each behavior. Experimental results demonstrate that MARO not only achieves significant improvements in social reasoning capabilities, but also that the abilities acquired through social simulation learning can effectively transfer to other tasks such as mathematical reasoning and instruction following. This reveals the tremendous potential of multi-agent social learning in enhancing the general reasoning capabilities of LLMs.
AgentGroupChat-V2: Divide-and-Conquer Is What LLM-Based Multi-Agent System Need
Jun 18, 2025Large language model based multi-agent systems have demonstrated significant potential in social simulation and complex task resolution domains. However, current frameworks face critical challenges in system architecture design, cross-domain generalizability, and performance guarantees, particularly as task complexity and number of agents increases. We introduces AgentGroupChat-V2, a novel framework addressing these challenges through three core innovations: (1) a divide-and-conquer fully parallel architecture that decomposes user queries into hierarchical task forest structures enabling dependency management and distributed concurrent processing. (2) an adaptive collaboration engine that dynamically selects heterogeneous LLM combinations and interaction modes based on task characteristics. (3) agent organization optimization strategies combining divide-and-conquer approaches for efficient problem decomposition. Extensive experiments demonstrate AgentGroupChat-V2's superior performance across diverse domains, achieving 91.50% accuracy on GSM8K (exceeding the best baseline by 5.6 percentage points), 30.4% accuracy on competition-level AIME (nearly doubling other methods), and 79.20% pass@1 on HumanEval. Performance advantages become increasingly pronounced with higher task difficulty, particularly on Level 5 MATH problems where improvements exceed 11 percentage points compared to state-of-the-art baselines. These results confirm that AgentGroupChat-V2 provides a comprehensive solution for building efficient, general-purpose LLM multi-agent systems with significant advantages in complex reasoning scenarios. Code is available at https://github.com/MikeGu721/AgentGroupChat-V2.
CompBench: Benchmarking Complex Instruction-guided Image Editing
May 18, 2025While real-world applications increasingly demand intricate scene manipulation, existing instruction-guided image editing benchmarks often oversimplify task complexity and lack comprehensive, fine-grained instructions. To bridge this gap, we introduce, a large-scale benchmark specifically designed for complex instruction-guided image editing. CompBench features challenging editing scenarios that incorporate fine-grained instruction following, spatial and contextual reasoning, thereby enabling comprehensive evaluation of image editing models' precise manipulation capabilities. To construct CompBench, We propose an MLLM-human collaborative framework with tailored task pipelines. Furthermore, we propose an instruction decoupling strategy that disentangles editing intents into four key dimensions: location, appearance, dynamics, and objects, ensuring closer alignment between instructions and complex editing requirements. Extensive evaluations reveal that CompBench exposes fundamental limitations of current image editing models and provides critical insights for the development of next-generation instruction-guided image editing systems.
LITE: LLM-Impelled efficient Taxonomy Evaluation
Apr 02, 2025This paper presents LITE, an LLM-based evaluation method designed for efficient and flexible assessment of taxonomy quality. To address challenges in large-scale taxonomy evaluation, such as efficiency, fairness, and consistency, LITE adopts a top-down hierarchical evaluation strategy, breaking down the taxonomy into manageable substructures and ensuring result reliability through cross-validation and standardized input formats. LITE also introduces a penalty mechanism to handle extreme cases and provides both quantitative performance analysis and qualitative insights by integrating evaluation metrics closely aligned with task objectives. Experimental results show that LITE demonstrates high reliability in complex evaluation tasks, effectively identifying semantic errors, logical contradictions, and structural flaws in taxonomies, while offering directions for improvement. Code is available at https://github.com/Zhang-l-i-n/TAXONOMY_DETECT .
RECKON: Large-scale Reference-based Efficient Knowledge Evaluation for Large Language Model
Apr 01, 2025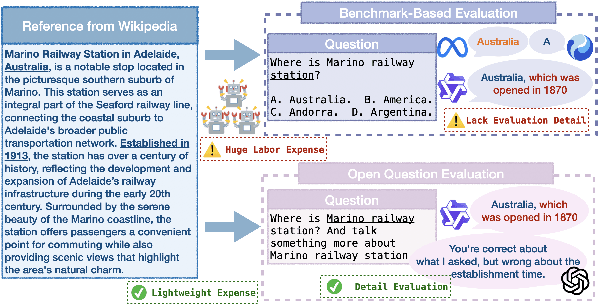
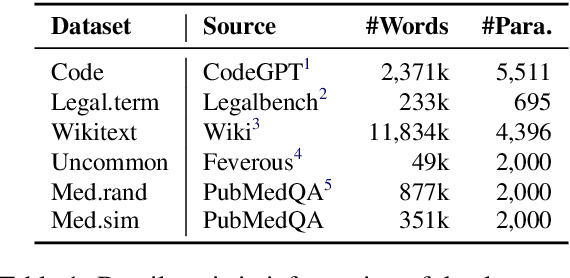
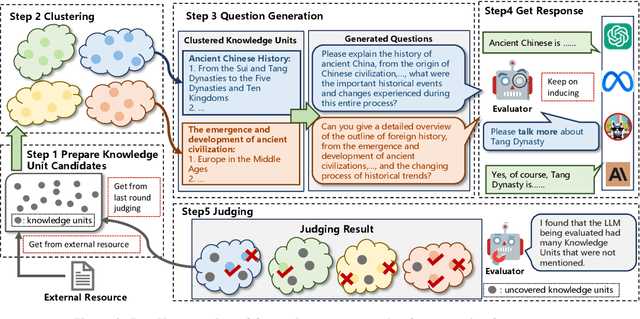
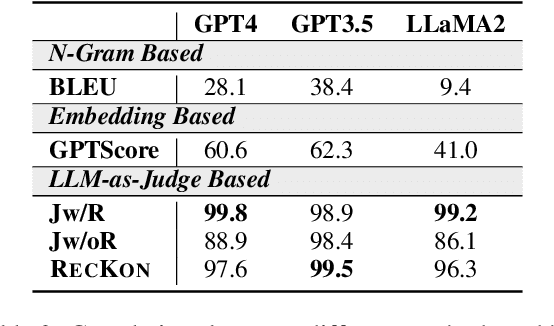
As large language models (LLMs) advance, efficient knowledge evaluation becomes crucial to verifying their capabilities. Traditional methods, relying on benchmarks, face limitations such as high resource costs and information loss. We propose the Large-scale Reference-based Efficient Knowledge Evaluation for Large Language Model (RECKON), which directly uses reference data to evaluate models. RECKON organizes unstructured data into manageable units and generates targeted questions for each cluster, improving evaluation accuracy and efficiency. Experimental results show that RECKON reduces resource consumption by 56.5% compared to traditional methods while achieving over 97% accuracy across various domains, including world knowledge, code, legal, and biomedical datasets. Code is available at https://github.com/MikeGu721/reckon
ToReMi: Topic-Aware Data Reweighting for Dynamic Pre-Training Data Selection
Apr 01, 2025



Pre-training large language models (LLMs) necessitates enormous diverse textual corpora, making effective data selection a key challenge for balancing computational resources and model performance. Current methodologies primarily emphasize data quality metrics and mixing proportions, yet they fail to adequately capture the underlying semantic connections between training samples and quality disparities within individual domains. We introduce ToReMi (Topic-based Reweighting for Model improvement), a novel two-stage framework that dynamically adjusts training sample weights according to their topical associations and observed learning patterns. Our comprehensive experiments reveal that ToReMi variants consistently achieve superior performance over conventional pre-training approaches, demonstrating accelerated perplexity reduction across multiple domains and enhanced capabilities on downstream evaluation tasks. Code is available at https://github.com/zxx000728/ToReMi.
GAPO: Learning Preferential Prompt through Generative Adversarial Policy Optimization
Mar 26, 2025Recent advances in large language models have highlighted the critical need for precise control over model outputs through predefined constraints. While existing methods attempt to achieve this through either direct instruction-response synthesis or preferential response optimization, they often struggle with constraint understanding and adaptation. This limitation becomes particularly evident when handling fine-grained constraints, leading to either hallucination or brittle performance. We introduce Generative Adversarial Policy Optimization (GAPO), a novel framework that combines GAN-based training dynamics with an encoder-only reward model to progressively learn and adapt to increasingly complex constraints. GAPO leverages adversarial training to automatically generate training samples of varying difficulty while utilizing the encoder-only architecture to better capture prompt-response relationships. Extensive experiments demonstrate GAPO's superior performance across multiple benchmarks, particularly in scenarios requiring fine-grained constraint handling, where it significantly outperforms existing methods like PPO, DPO, and KTO. Our results suggest that GAPO's unique approach to preferential prompt learning offers a more robust and effective solution for controlling LLM outputs. Code is avaliable in https://github.com/MikeGu721/GAPO.